
为方便用户快速体验大模型边缘计算盒产品能力,我们提供远程测试访问方式。用户可通过以下三种数据源接入系统进行算法验证:
- 上传本地视频文件
- 公网视频流(如萤石云 RTSP)
- 国标协议(GB28181 )摄像头接入
1. 注意事项(重要!!!)
- 访问系统页面的电脑基本要求:≥ WIN11、≥ I5 CPU、必须使用Chrome浏览器新版本(版本号≥138)!
- 远程访问,受限于访问人数和公有云带宽,可能会有卡顿或实时画面播放不出来的情况!
- 由于软件支持自定义LOGO、标题等,测试用户会做修改,可能每次登陆会有显示差异!
- 上传的视频文件时长≥ 1 分钟!,视频文件< 200 MB!
2. 上传数据源
2.1 如何上传视频文件
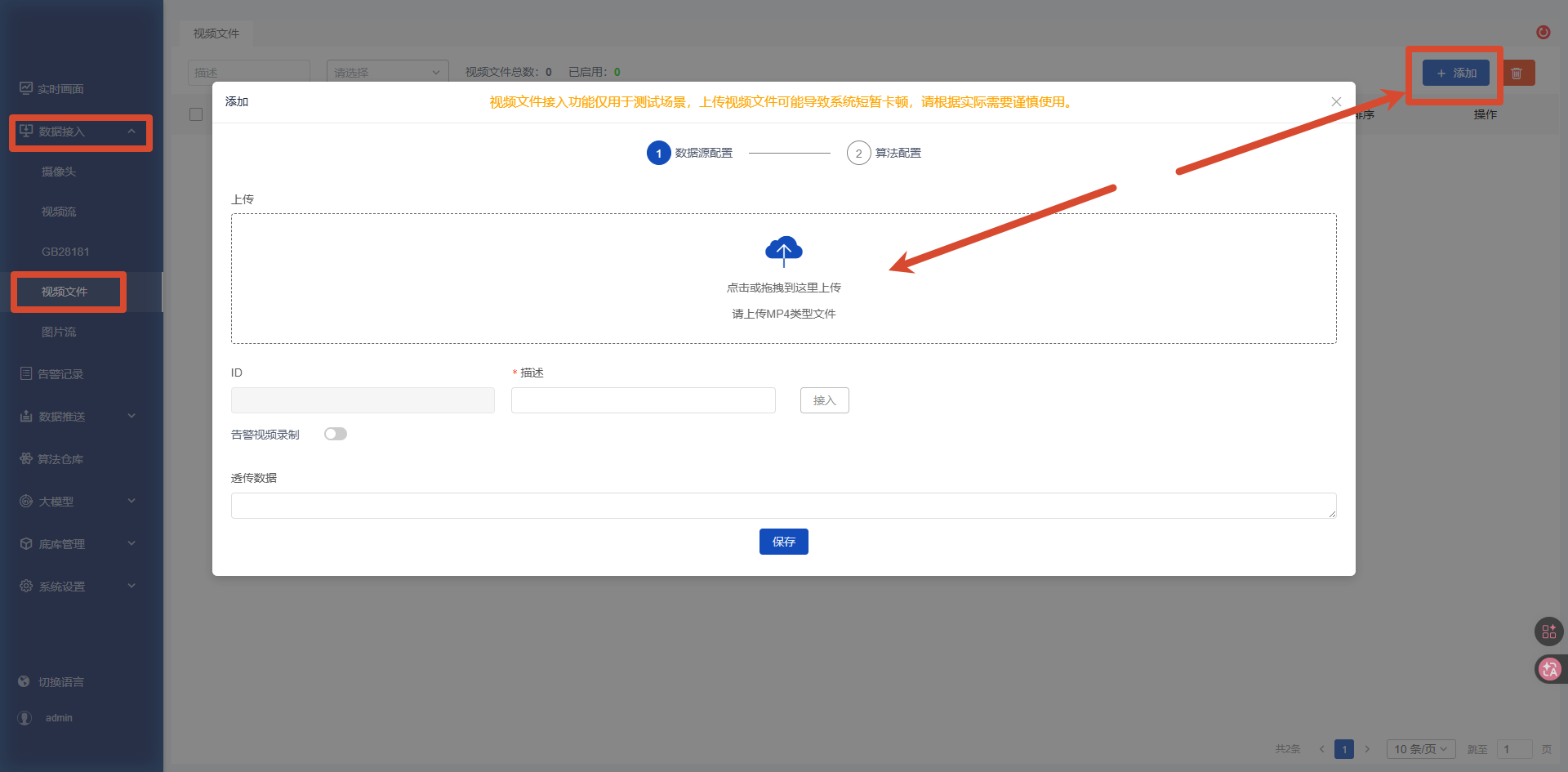
- 在【视频接入】->【视频文件】点击【添加】按钮,并上传
mp4格式的视频文件。 - 上传完成之后,点击【接入】之后并【保存】。
- 配置对应的算法测试算法效果
2.2 使用公网视频流
以萤石云为例:
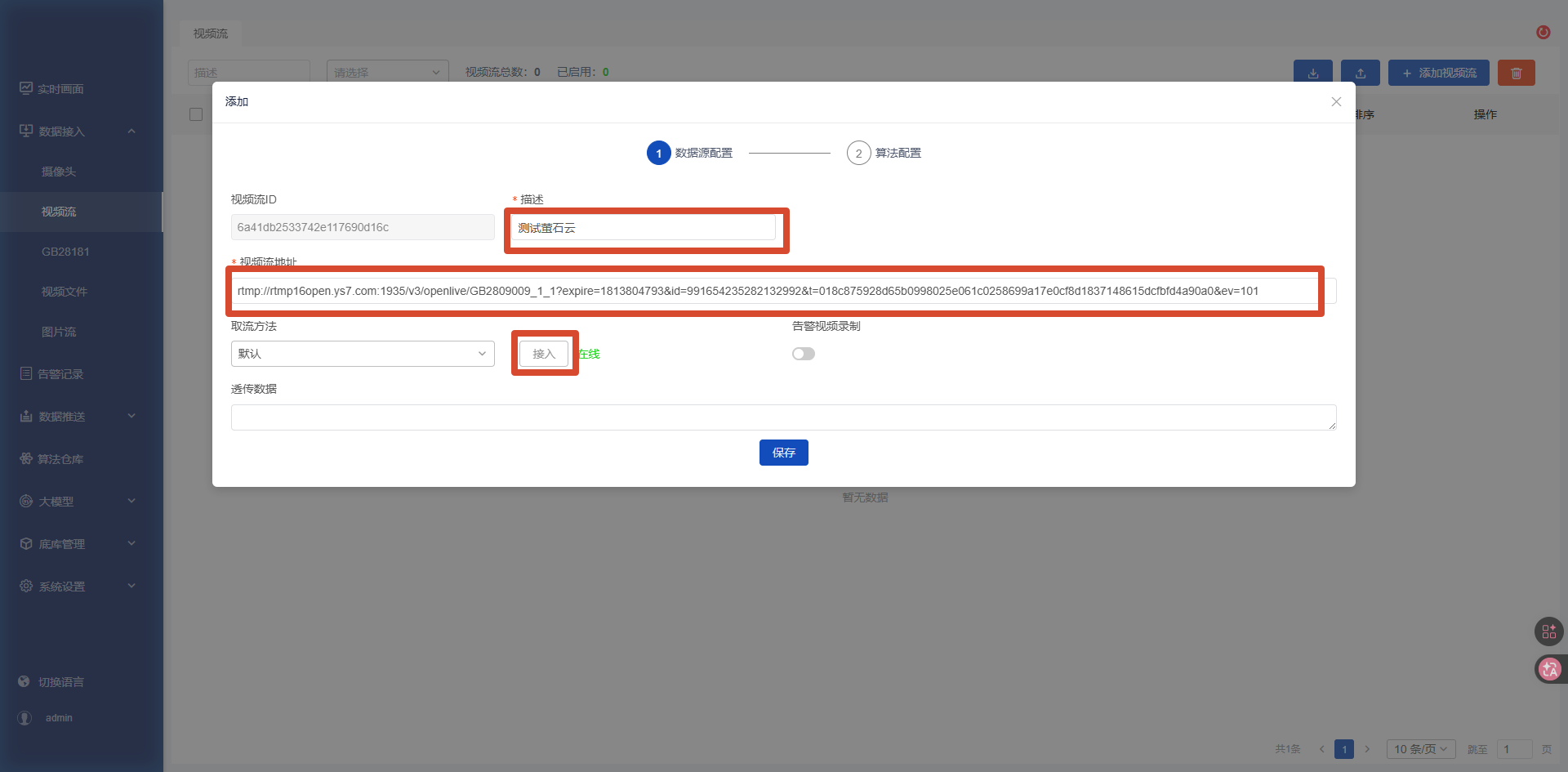
- 在【视频接入】->【视频流】中填写描述以及公网视频流地址后点击【接入】并【保存】。
- 配置对应的算法测试算法效果
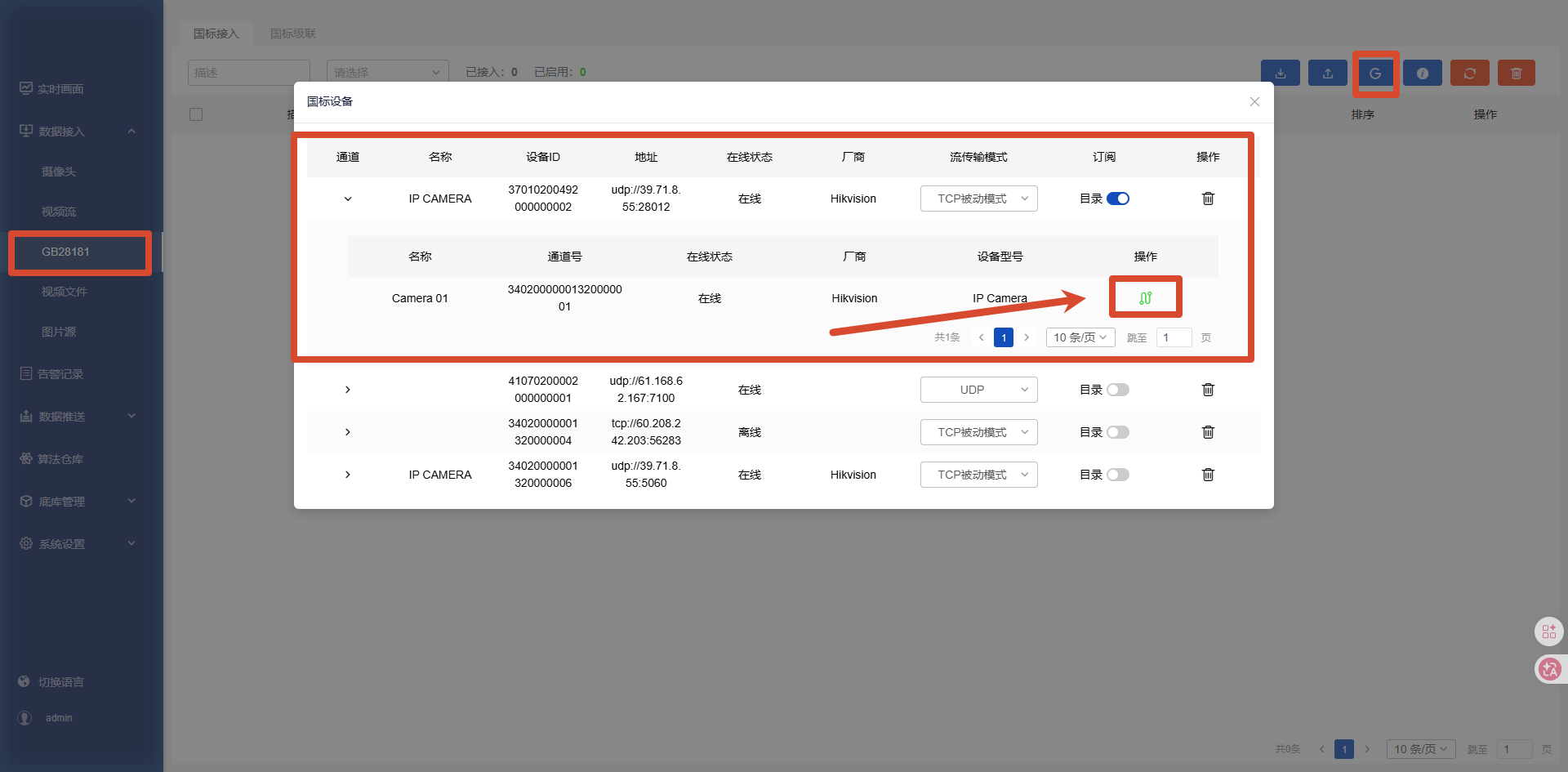
2.3 使用国标(GB28181)接入
GB28181接入是针对相对专业人员进行的配置,适用于专业视频监控场景,可直接接入真实摄像头实现实时分析。
摄像头配置:
配置 SIP 服务器地址等信息
设置设备 ID / 通道 ID
启用国标协议推流
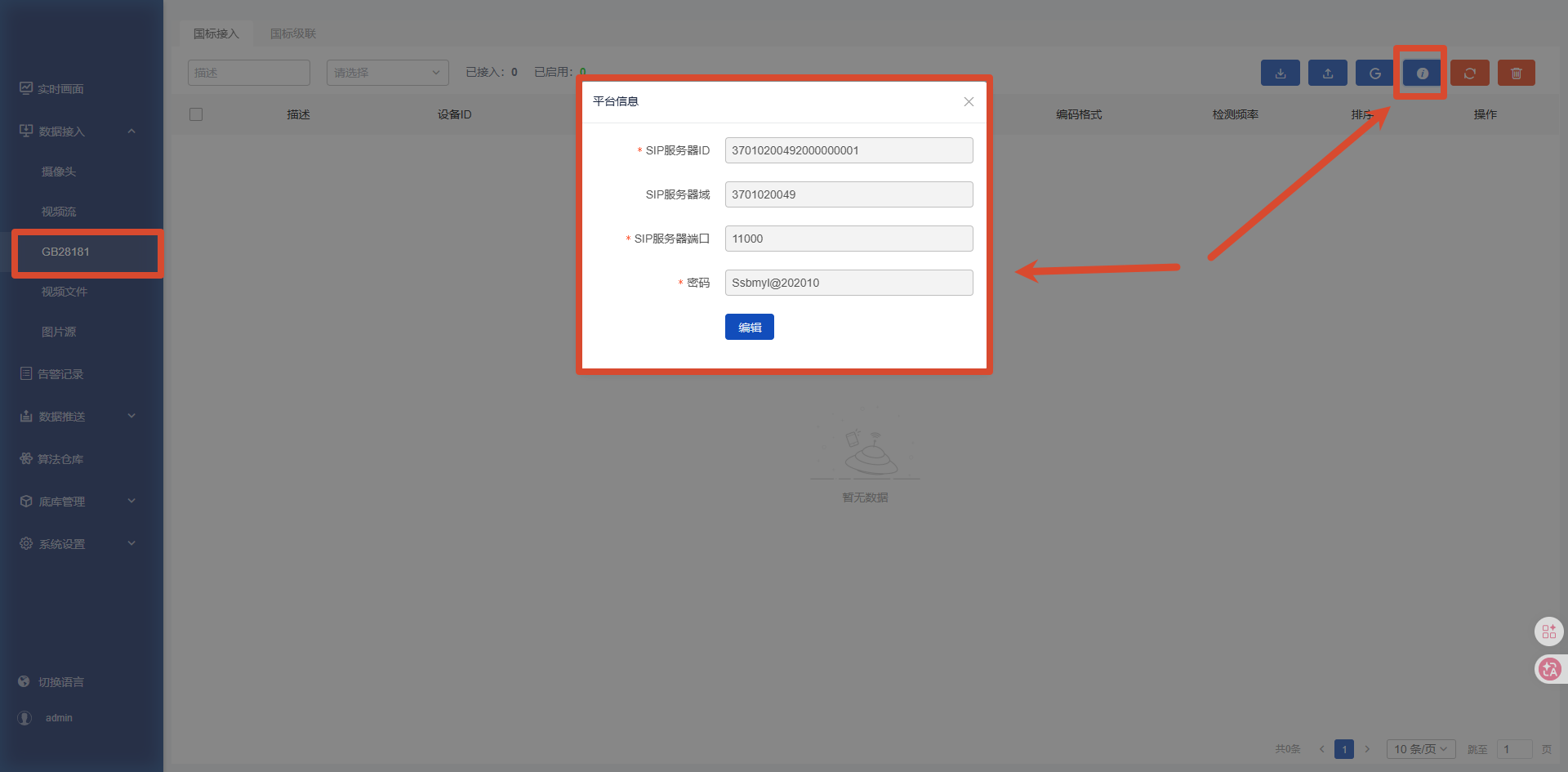
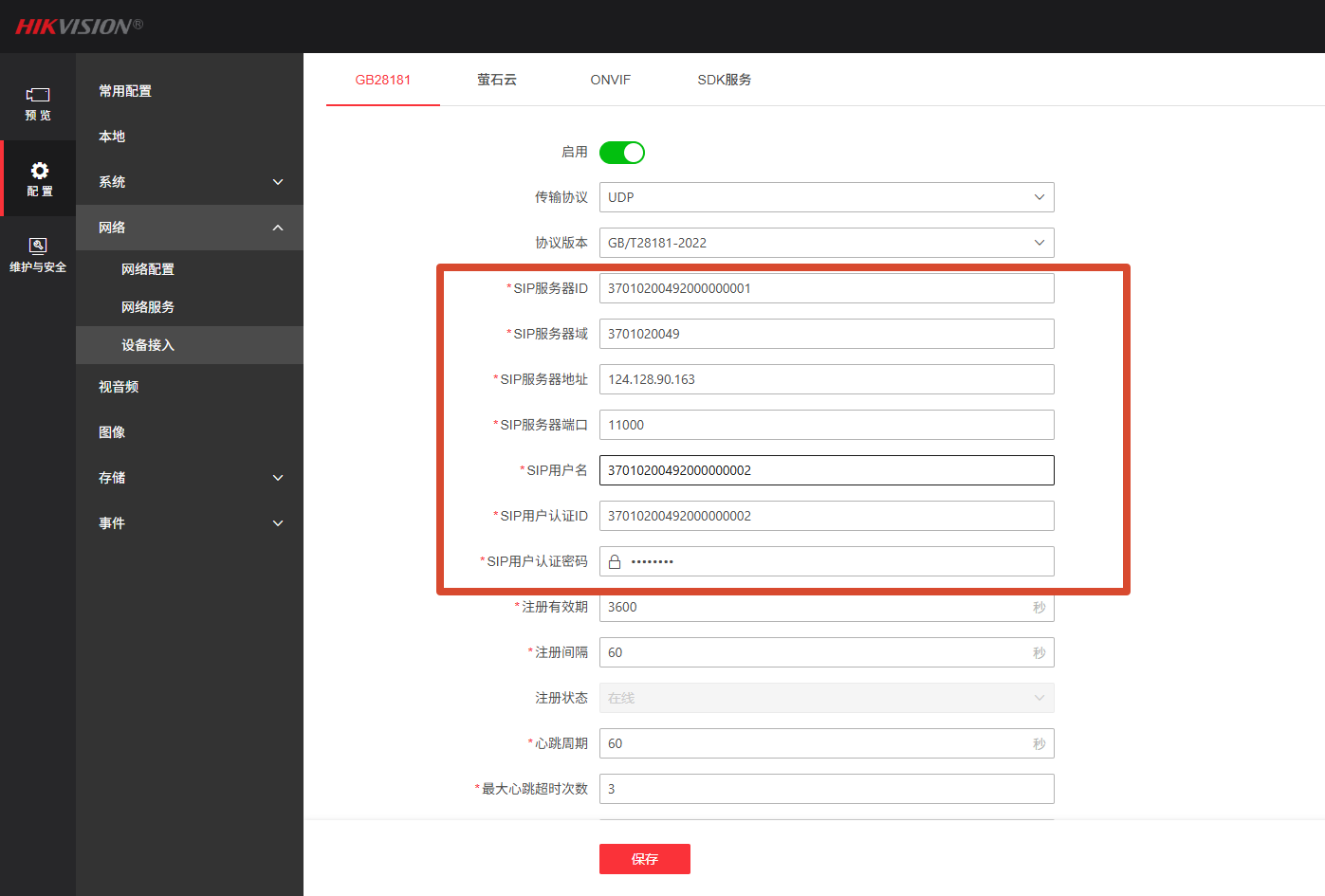
盒子接入:
复审任务
用于构建:小模型初筛 + 大模型复核 的协同分析流程。
1. 功能概述
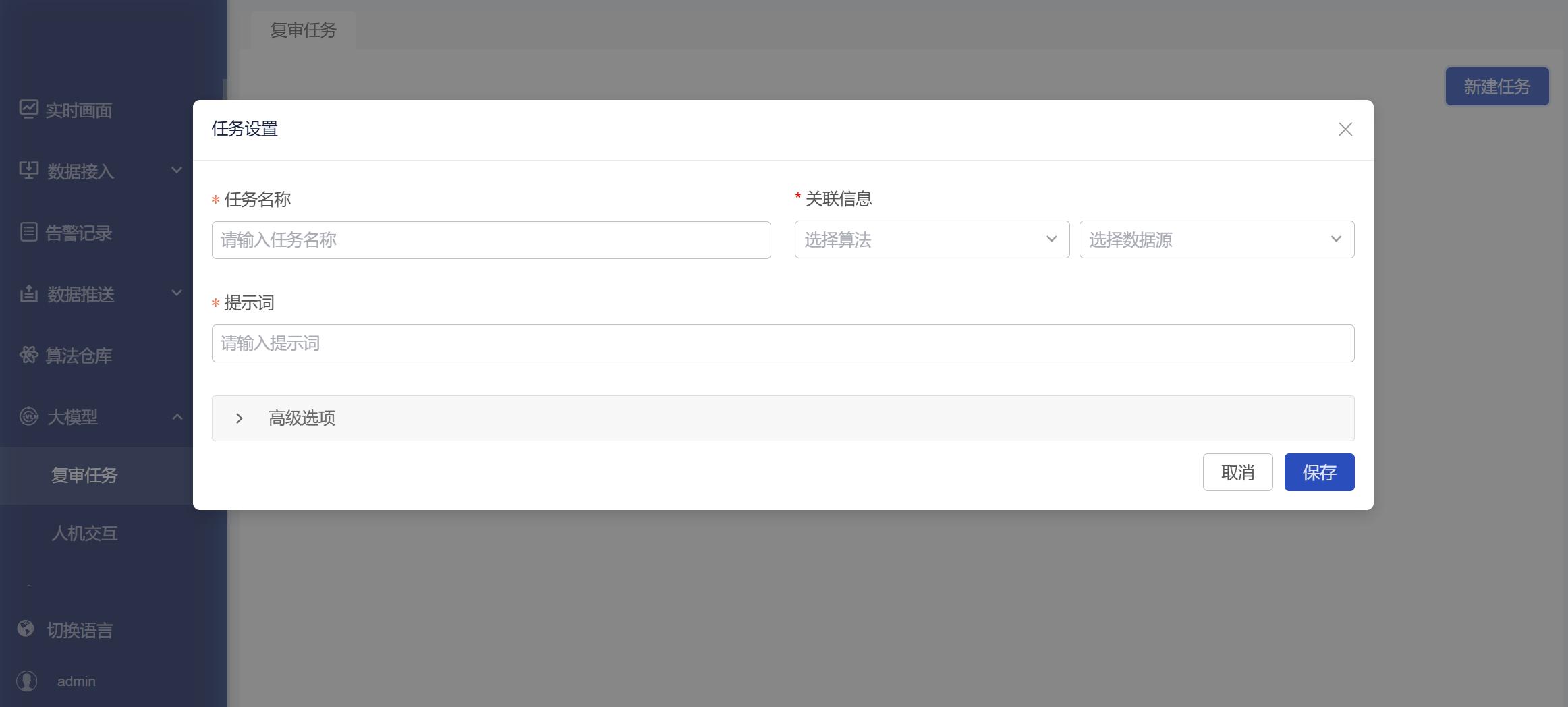
- 进入复审任务页面,点击【大模型】-【复审任务】。
- 大模型复审任务用于对小模型产生的告警结果进行二次审核,确认告警事件是否真实成立。
- 当小模型检测到疑似告警事件后,由大模型根据用户配置的复审提示词,对告警内容进行语义理解、状态判断和逻辑确认,判断该告警是否真实成立。
- 该功能可有效降低小模型误报,提高告警结果的准确性和可信度。
2. 配置内容
创建大模型复审任务时,需要配置以下内容:
| 配置项 | 说明 |
|---|---|
| 任务名称 | 用于区分不同的复审任务 |
| 绑定算法 | 选择需要复审的小模型算法 |
| 绑定数据源 | 选择复审任务作用的视频源或数据源 |
| 提示词 | 描述大模型需要判断的内容、规则和输出格式 |
| 高级选项 | 配置复审相关的扩展参数 |
人机交互
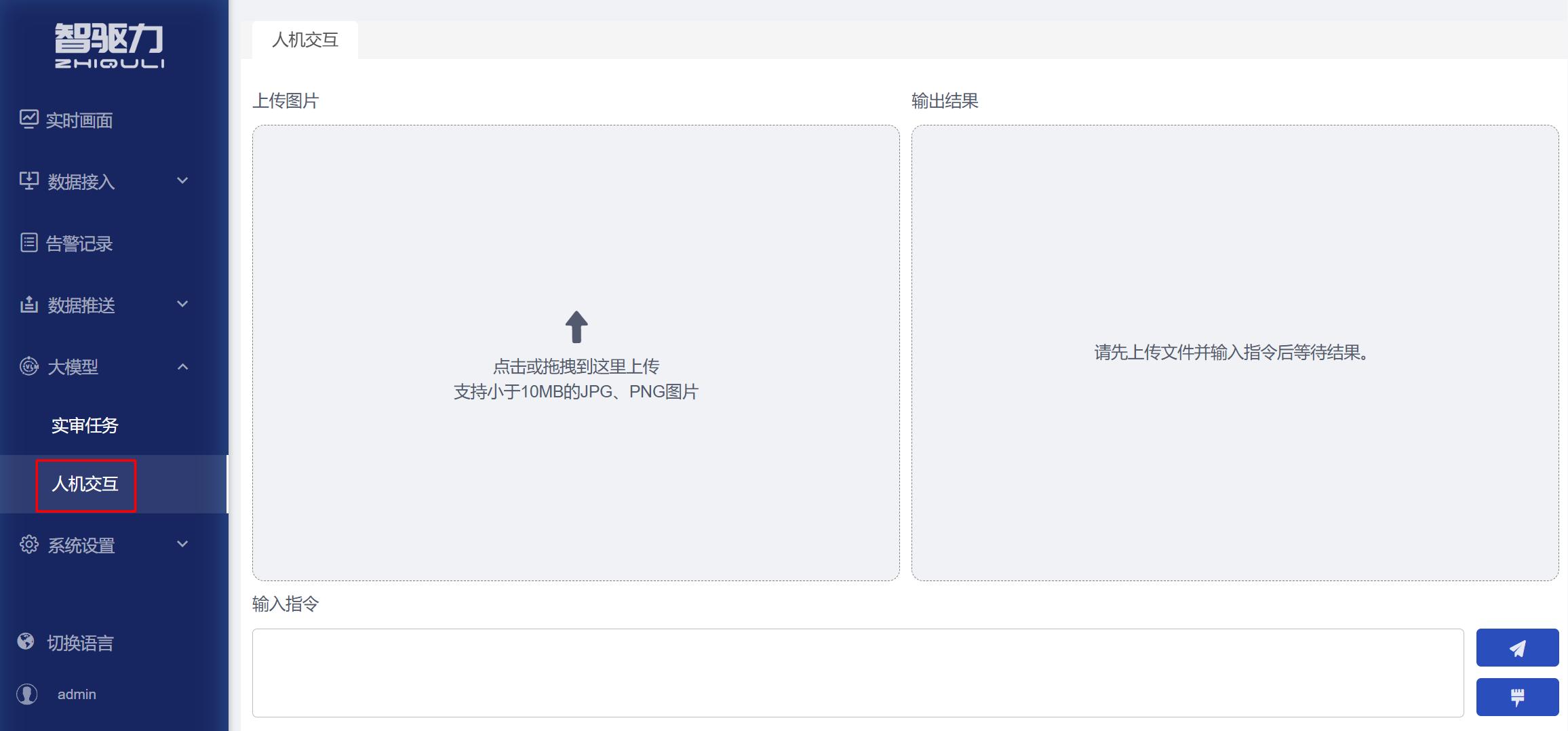
用于上传图片并输入问题,由大模型对图片内容进行分析回答。该功能既可以用于直接提问,也可以用于辅助设计和验证实审任务提示词。
1. 功能概述
- 【人机交互】提供图片问答式的大模型分析能力。用户可上传一张图片,并输入自然语言问题,系统会结合图片内容和用户问题返回分析结果。
- 该功能适合临时性图像分析、现场问题确认、实审结果排查、提示词设计和提示词效果验证。
- 人机交互不面向长期自动运行的视频源,而是面向单张图片的即时分析。用户可以根据当前图片直接提问,快速获得大模型判断结果。
实审任务
实审任务用于创建大模型算法,用户在创建算法前,需要先理解算法类别、可视化展示和大模型思考过程三个关键配置。
1. 功能概述
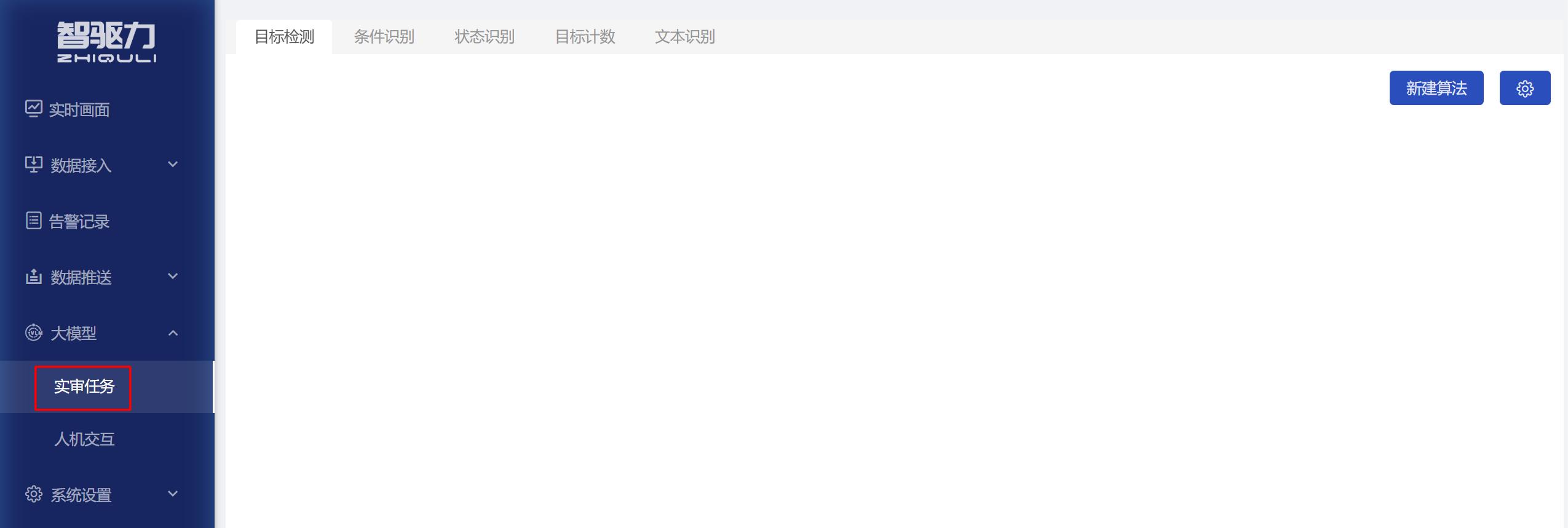
- 进入实审任务页面,点击【大模型】-【实审任务】。
- 系统支持按业务场景创建不同类型的大模型算法,包括目标检测、条件识别、状态识别、目标计数、文本识别。
2. 通用配置说明
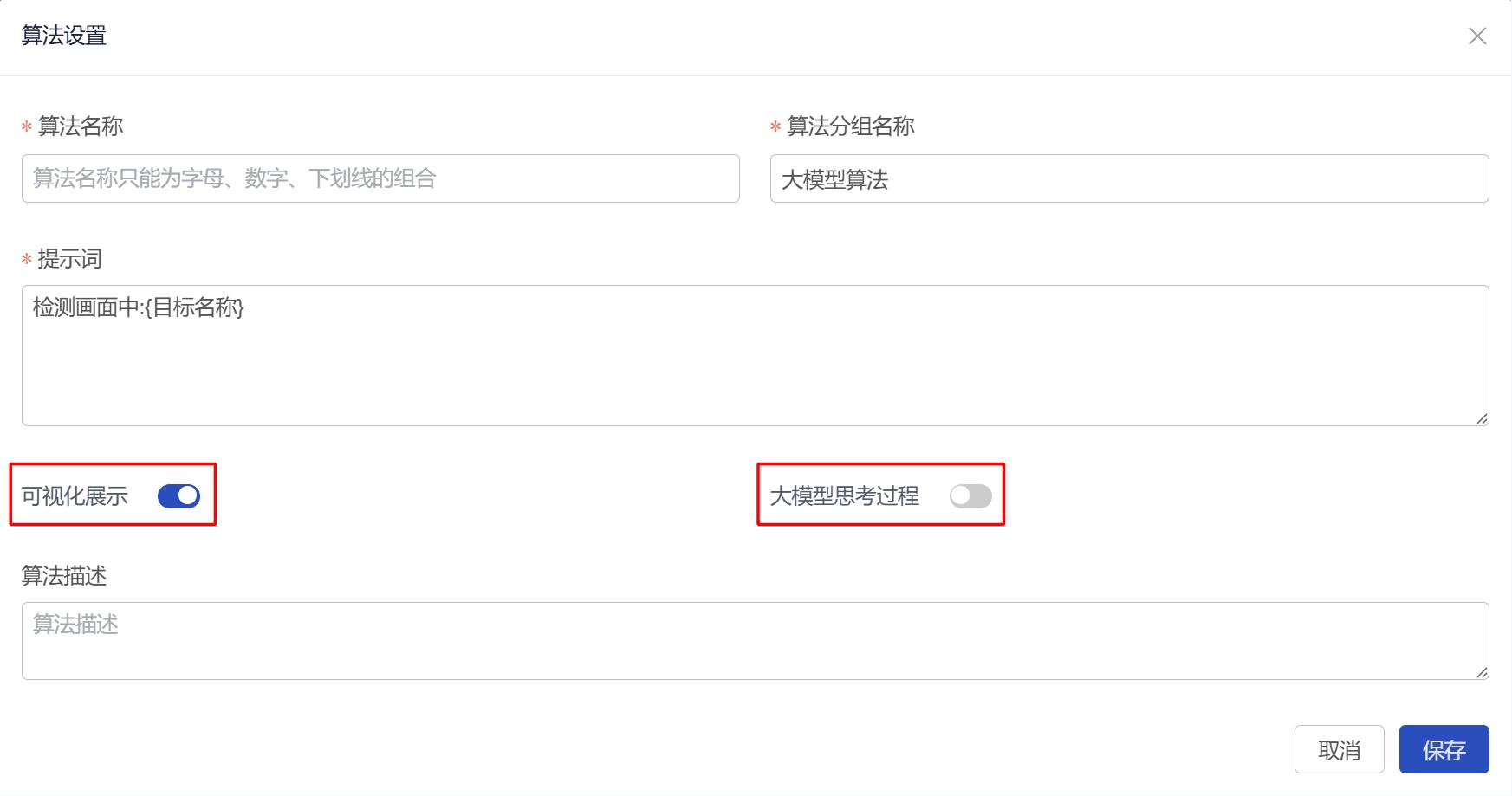
2.1 可视化展示
- 功能作用:用于控制是否输出目标检测框。
- 开启效果:返回目标位置并绘制检测框。
- 使用影响:增加推理耗时,可能影响判定稳定性。
- 使用建议:
- 检测内容简单、目标清晰时,可开启,用于查看目标检测框。
- 检测内容复杂、依赖动作/状态/关系/多条件判断时,建议关闭或谨慎开启。
- 开启后模型需要同时完成结果判断和目标定位,增加推理难度,在模型能力不足或画面复杂时,可能导致结果不稳定或错误。
- 如果需要分析误报、漏报或确认目标位置,可临时开启【可视化展示】进行排查,完成分析后再根据实际效果决定是否长期启用。
2.2 大模型思考过程
- 功能作用:用于控制是否输出思维链。
- 开启效果:输出思维链,有助于理解模型为什么命中。
- 使用影响:增加推理耗时,可能增加结果解析复杂度。
- 使用建议:
- 开启后会增加推理耗时。
- 对复杂语义、多条件判断、状态识别和关系识别任务,开启后有时能帮助模型更完整地分析画面,对结果有一定帮助。
- 建议新建算法和调试阶段可先开启,效果稳定后再根据实际需要决定是否长期启用。
3. 算法类别
3.1 目标检测
用于检测画面中是否存在某一类明确目标,并可根据需要输出目标所在位置。
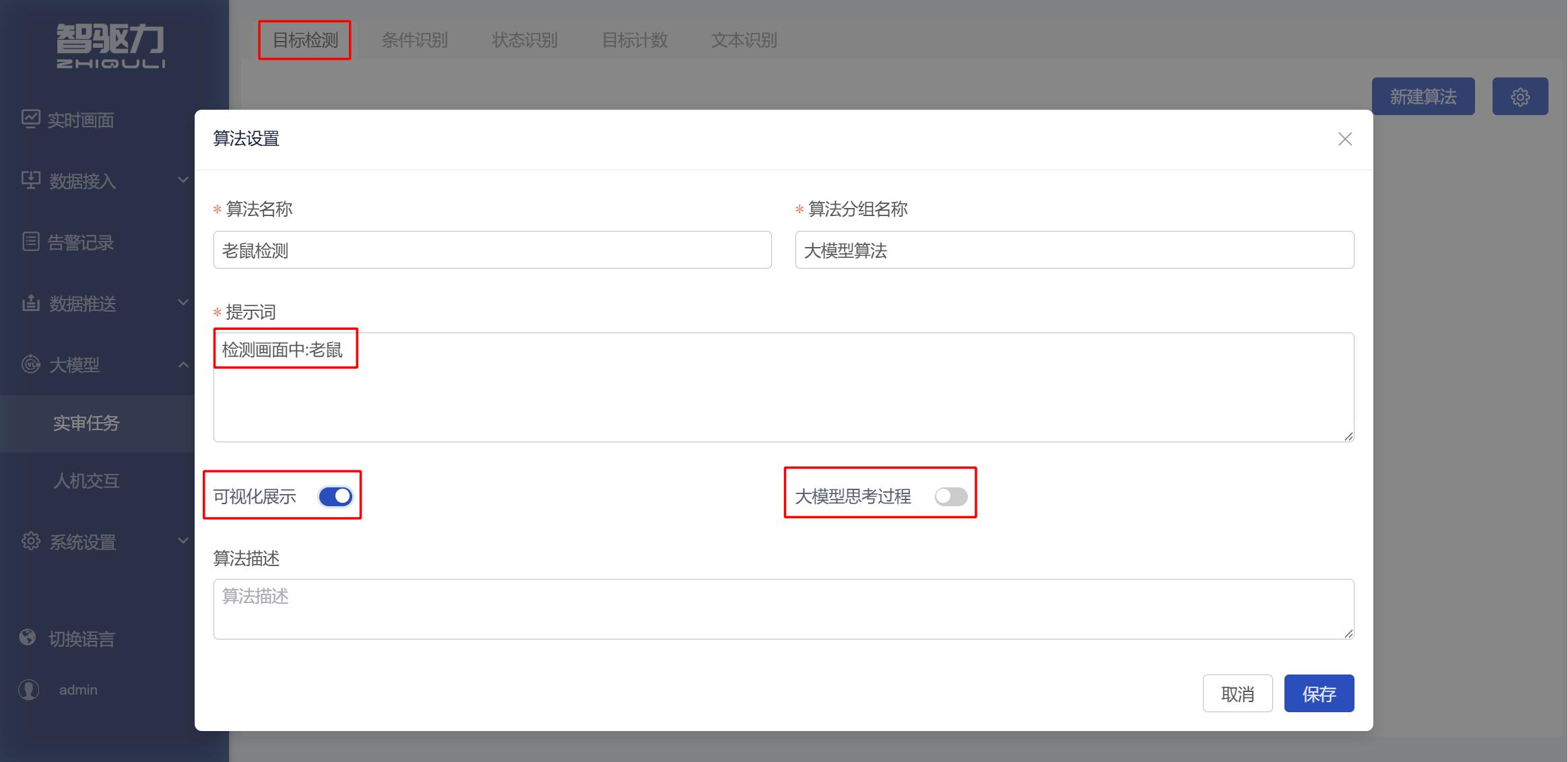
适用场景
适用于目标本身清晰、外观特征直接、边界相对明确的检测任务。该类别主要解决“画面中是否存在某个明确目标”的问题。
| 类型 | 示例 |
|---|---|
| 人员类 | 人员、工人、行人 |
| 车辆类 | 小汽车、货车、叉车、工程车 |
| 物品类 | 灭火器、水桶、梯子、工具、货物 |
| 设备设施类 | 机器设备、门、窗、护栏、配电柜 |
不适用场景
目标检测不适合直接用于复杂行为、复杂状态或多条件判断任务。此类任务并非不能实现,而是应优先选择【条件识别】或【状态识别】。
| 不建议写法 | 原因 |
|---|---|
| 正在打电话的人 | 需要同时判断人员、手机、手部动作和手机位置 |
| 正在抽烟的人 | 需要同时判断人员、手部动作、香烟目标和接触关系 |
| 未挂安全绳的人 | 需要判断人员与安全装备的佩戴或连接状态 |
| 跨梯子的人 | 需要判断人体姿态、梯子位置和动作关系 |
填写建议
创建目标检测算法时,提示词应尽量简洁,只描述需要检测的目标,不要把动作、状态或业务条件写进目标名称。
3.2 条件识别
用于判断画面中是否存在同时满足多个条件的目标。
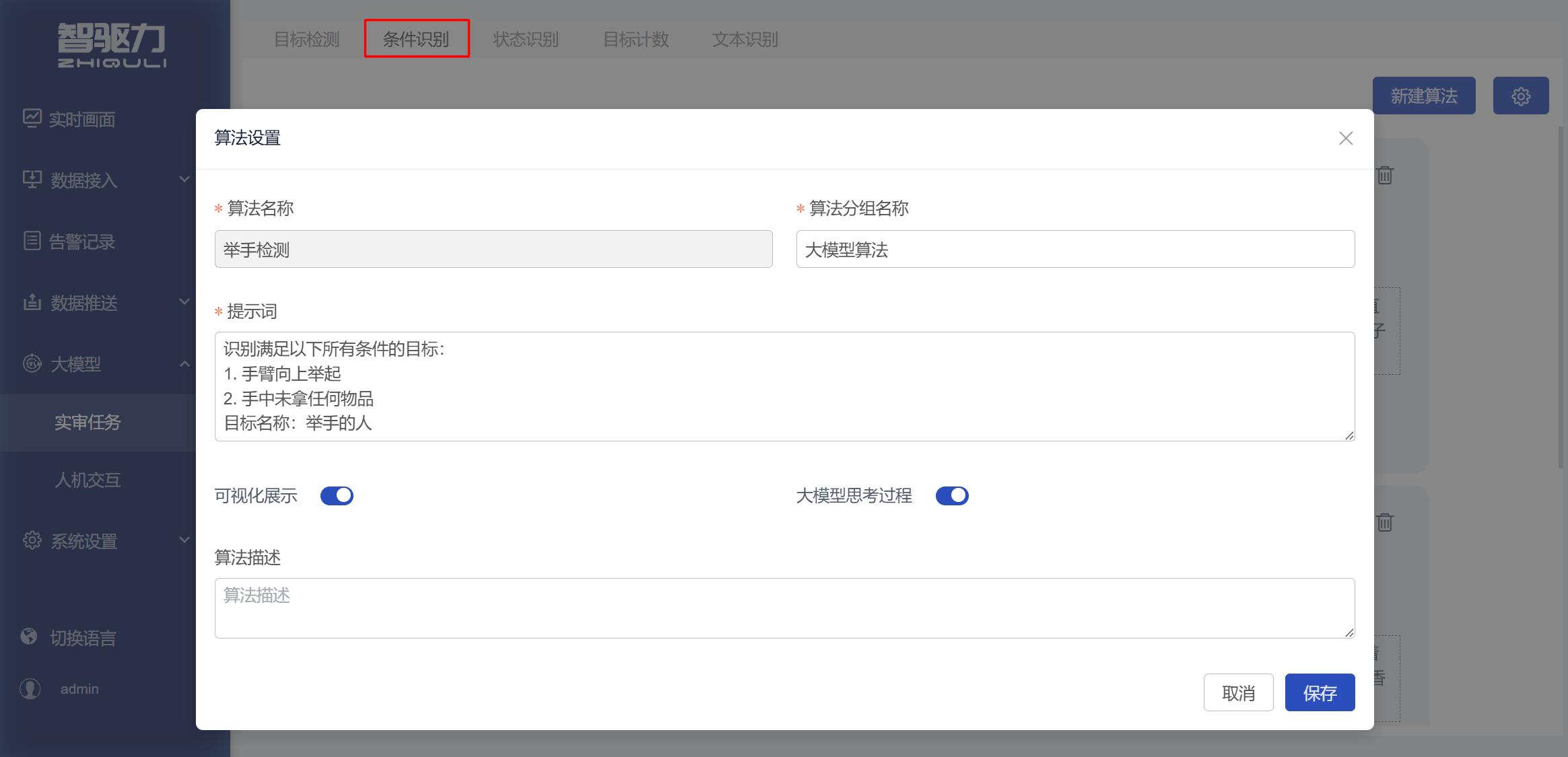
适用场景
适用于需要同时满足多个条件才能判断目标是否命中的任务。该类别主要解决“画面中是否存在满足指定条件的目标”的问题。
| 类型 | 示例 |
|---|---|
| 动作行为类 | 打电话、抽烟、举手、攀爬、跨越 |
| 姿态关系类 | 站在梯子上、靠近设备、进入区域、越过护栏 |
| 穿戴属性类 | 未戴安全帽、未穿反光衣、未戴口罩、未穿防护鞋 |
| 多条件判断类 | 人员在指定区域内停留、车辆停在禁停区域、人员手持指定物品 |
不适用场景
条件识别不适合单纯目标检测、数量统计或文字读取任务。此类任务应优先选择对应的算法类别。
| 不建议写法 | 原因 |
|---|---|
| 人员 | 只是检测明确目标,应选择【目标检测】 |
| 车辆 | 只是检测明确目标,应选择【目标检测】 |
| 统计人员数量 | 最终结果需要数量,应选择【目标计数】 |
| 识别门牌文字 | 最终结果需要文字内容,应选择【文本识别】 |
| 灭火器离位 | 更偏向业务异常状态判断,建议选择【状态识别】 |
填写建议
创建条件识别算法时,应将判断条件逐条拆开填写,不要把多个条件压缩成一个目标名称。每个条件应尽量明确、可观察、可判断。
3.3 状态识别
用于根据业务规则判断画面中是否存在异常状态、缺失状态、占用状态或其他告警触发条件。
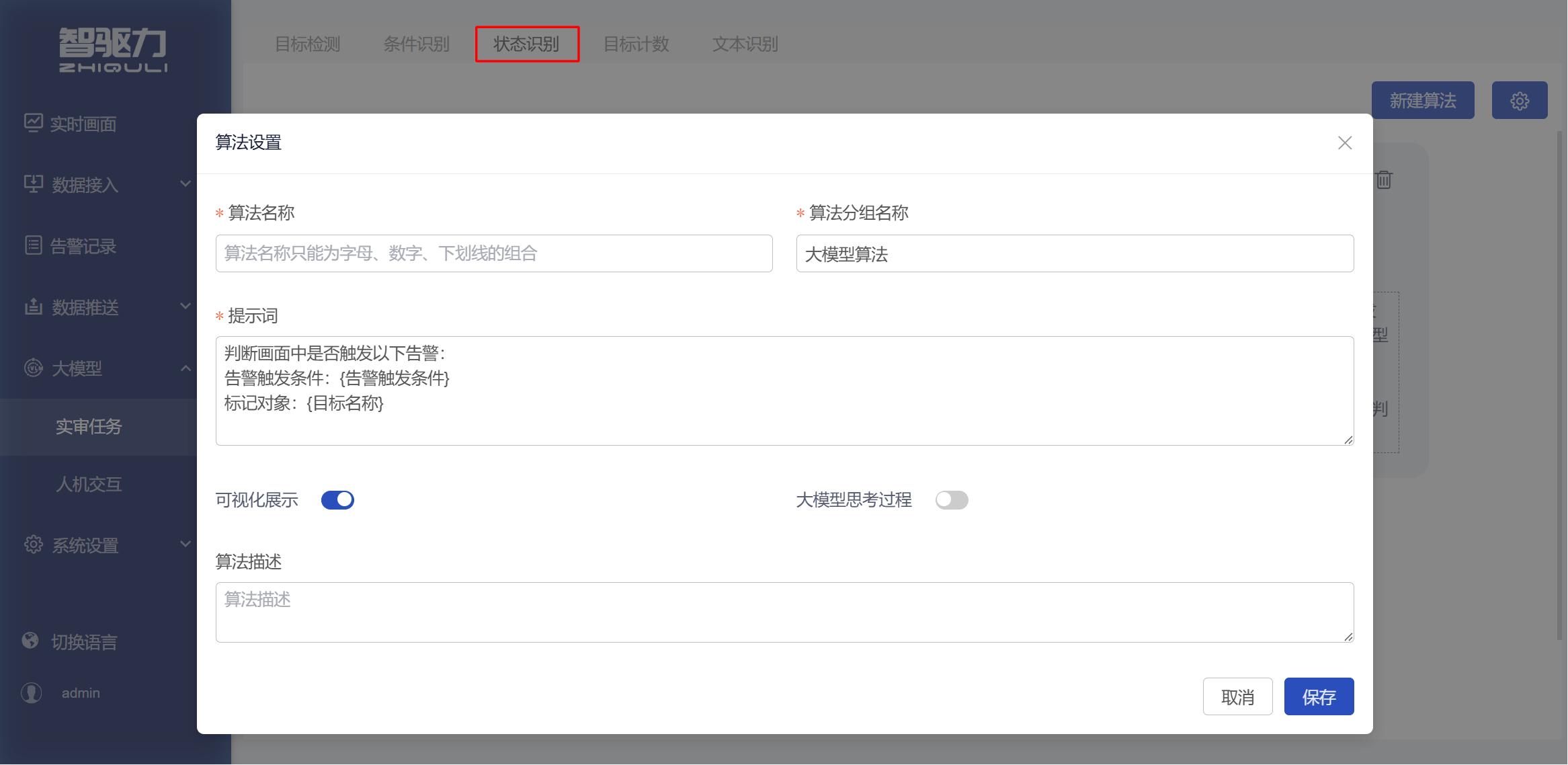
适用场景
适用于判断画面中是否触发某种业务状态、异常状态或告警条件的任务。该类别主要解决“当前画面是否满足某个告警规则”的问题。
| 类型 | 示例 |
|---|---|
| 离位缺失类 | 灭火器离位、设备缺失、物品不在指定位置 |
| 占用异常类 | 通道占用、消防通道堵塞、区域被占用 |
| 开关状态类 | 门打开、柜门未关闭、设备盖板打开 |
| 值守状态类 | 岗位无人值守、人员离岗、区域无人 |
| 环境状态类 | 烟雾异常、物料堆放异常 |
不适用场景
状态识别不适合单纯检测目标、统计数量或读取文字内容。此类任务应优先选择对应的算法类别。
| 不建议写法 | 原因 |
|---|---|
| 人员 | 只是检测明确目标,应选择【目标检测】 |
| 车辆 | 只是检测明确目标,应选择【目标检测】 |
| 统计区域内人数 | 最终结果需要数量,应选择【目标计数】 |
| 识别设备铭牌文字 | 最终结果需要文字内容,应选择【文本识别】 |
| 打电话的人 | 更偏向多个条件共同判断,建议选择【条件识别】 |
填写建议
创建状态识别算法时,应重点写清“什么情况算触发告警”。如果是异常状态、缺失状态或否定类判断,应明确说明满足条件和不满足条件,避免模型理解错误。
3.4 目标计数
用于统计画面中指定目标的数量。
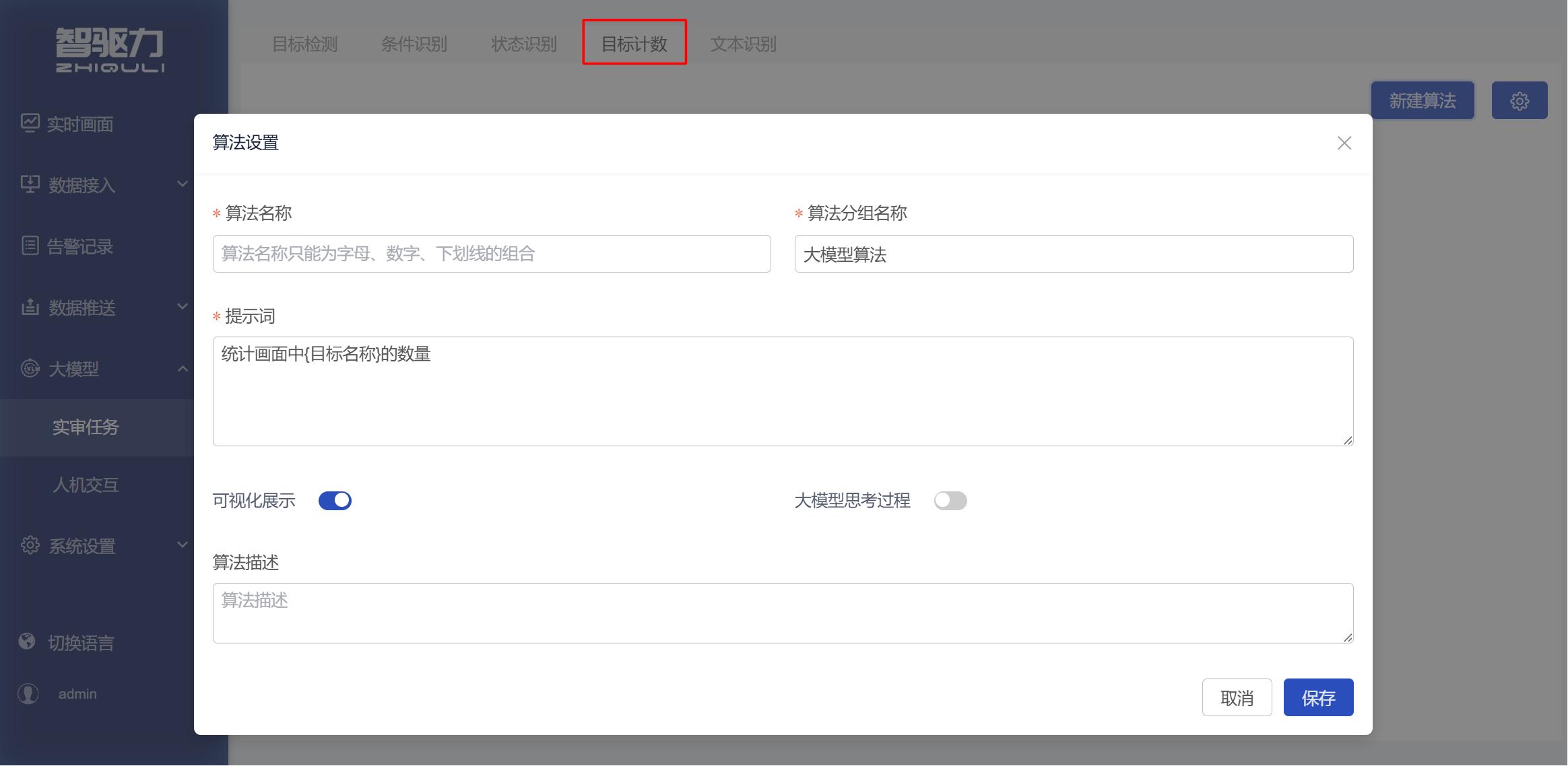
适用场景
适用于对少量、清晰、边界明确的目标进行数量统计。该类别主要解决“画面中有多少个指定目标”的问题。
| 类型 | 示例 |
|---|---|
| 人员计数类 | 区域内人员数量、岗位区域人数 |
| 车辆计数类 | 停车位车辆数量、通道内车辆数量 |
| 物品计数类 | 水桶数量、灭火器数量、货物数量 |
| 设备设施计数类 | 设备数量、工具数量、标识牌数量 |
能力边界
-
目标计数适合少量目标统计。当画面中目标数量较少、目标之间遮挡较少、目标边界清晰时,统计效果相对更稳定。
-
当目标数量较多时,尤其是目标密集排列、互相遮挡、大小差异明显或背景复杂时,大模型计数结果可能不准确。
-
因此,不建议将该类别用于高密度目标的精确计数任务。
不适用场景
目标计数不适合复杂密集场景、严重遮挡场景或对数量精度要求很高的任务。
| 不建议场景 | 原因 |
|---|---|
| 密集人群计数 | 人员数量多且互相遮挡,容易漏数或估算错误 |
| 大量货物计数 | 数量较多时模型容易输出近似值 |
| 超过 10 个目标的精确计数 | 当前模型难以稳定逐个识别并准确统计 |
| 小目标批量计数 | 目标过小或边界不清时容易漏检 |
| 远距离车辆计数 | 目标尺寸小、遮挡多,计数稳定性差 |
填写建议
创建目标计数算法时,应明确统计对象、统计范围和统计口径。建议配合检测区域使用,只统计指定区域内清晰可见的目标。
3.5 文本识别
用于识别画面中清晰可辨的文字内容。
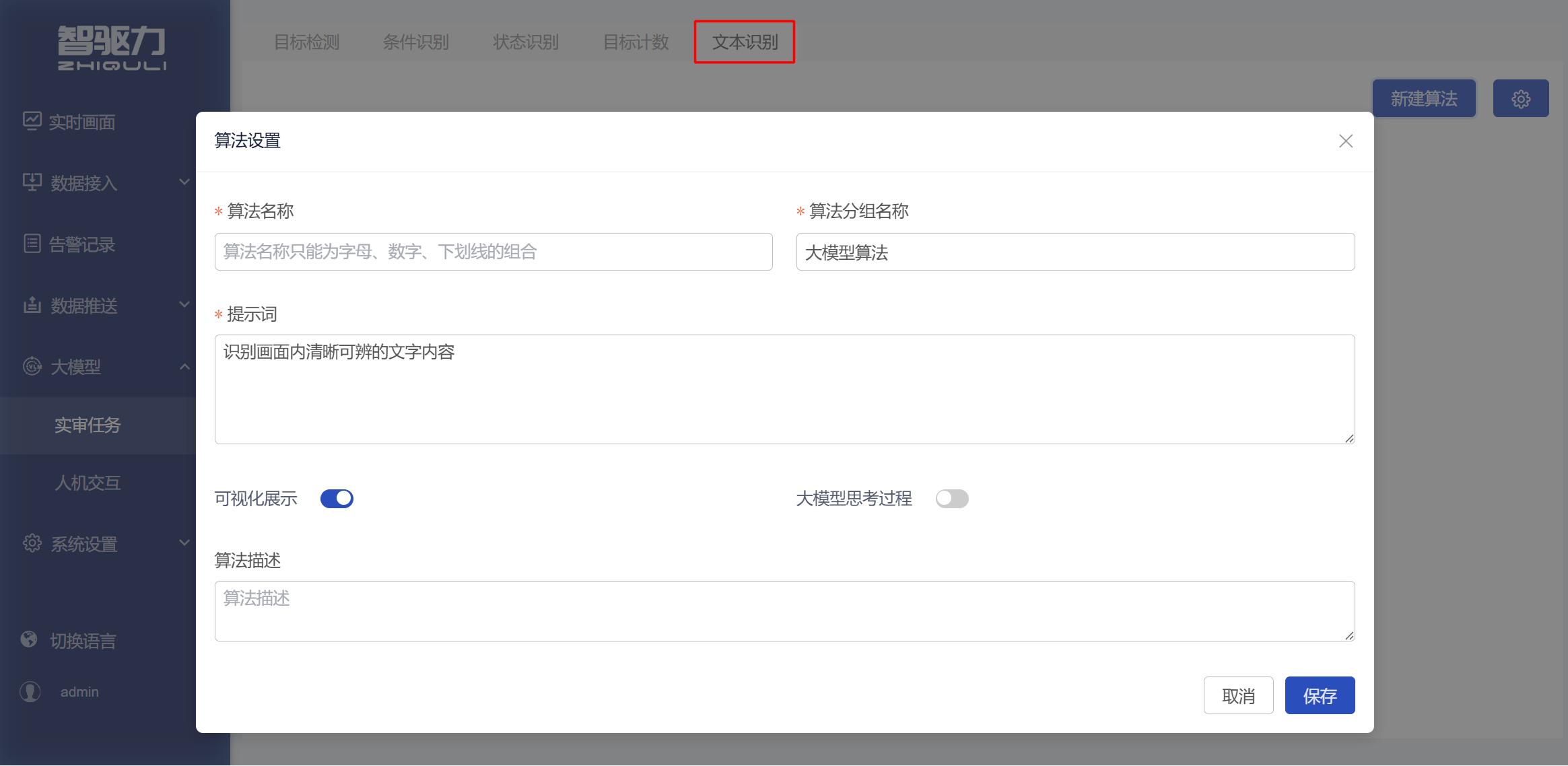
适用场景
适用于识别画面中位置相对明确、内容清晰可见的文字。该类别主要解决“画面中的文字是什么”的问题。
| 类型 | 示例 |
|---|---|
| 标识牌类 | 告示牌、警示牌、门牌、指示牌 |
| 店招铭牌类 | 店铺招牌、设备铭牌、产品标签 |
| 屏幕文字类 | 设备屏幕、仪表显示、电子看板 |
| 单据票据类 | 票据编号、单据文字、标签内容 |
| 区域文字类 | 指定 ROI 内的文字、指定物体上的文字 |
能力边界
-
文本识别适合识别清晰、无遮挡、位置明确的文字。建议配合检测区域使用,限定需要识别的文字范围,避免模型读取无关文字。
-
当文字过小、模糊、倾斜、遮挡、反光严重,或画面中同时存在时间戳、水印、摄像头编号、背景文字等干扰内容时,识别结果可能不稳定。此类场景中,模型可能漏读、误读,甚至把无关文字当成目标文字输出。
不适用场景
文本识别不适合全图泛化 OCR、复杂文档识别或模糊文字识别任务。
| 不建议场景 | 原因 |
|---|---|
| 识别整张图片中的所有文字 | 容易被时间戳、水印、背景文字干扰 |
| 识别模糊或过小文字 | 文字特征不清晰,容易误读或漏读 |
| 识别远距离文字 | 分辨率不足,结果不稳定 |
| 识别复杂票据全文 | 文字多、结构复杂,不适合直接全量识别 |
| 识别被遮挡或反光文字 | 关键信息不可见,容易输出错误内容 |
填写建议
创建文本识别算法时,应明确要识别哪一块文字、文字所在位置或所属对象。建议配合检测区域使用,并说明需要忽略的干扰文字。
人机交互
用于上传图片并输入问题,由大模型对图片内容进行分析回答。该功能既可以用于直接提问,也可以用于辅助设计和验证实审任务提示词。
1. 基础功能概述
- 【人机交互】提供图片问答式的大模型分析能力。用户可上传一张图片,并输入自然语言问题,系统会结合图片内容和用户问题返回分析结果。
- 该功能适合临时性图像分析、现场问题确认、实审结果排查、提示词设计和提示词效果验证。
- 与【实审任务】不同,人机交互不面向长期自动运行的视频源,而是面向单张图片的即时分析。用户可以根据当前图片直接提问,快速获得大模型判断结果。
2. 辅助设计提示词
-
用户可上传典型样本图片,并尝试不同的提问方式,观察大模型对目标、条件和规则的理解是否符合预期。
-
对于复杂任务,可通过人机交互先验证判断逻辑,再整理成实审任务中的正式提示词。
-
例如需要创建“打电话识别”算法时,可先上传样本图片,分别询问“画面中是否有人手持手机”“手机是否靠近耳部”“是否可以判断为正在打电话”,再根据模型回答整理出更清晰的条件识别提示词。
-
对于误报或漏报样本,也可通过人机交互辅助分析原因,判断是目标不清晰、条件描述不完整、检测区域不合理,还是提示词需要补充排除条件。
回复