
边缘视频AI分析,已经发展了6~9年了。这是一块超级广阔的市场大蛋糕,由于赛道的特殊性(场景过于碎片化,AI研发重投入之后,很难形成规模化回报),导致了一直难有顶级的AI公司下场博弈。诸如海康此类的公司,当它做完大交通等领域的视频AI场景之后,对于其它场景,始终抱有一种食之无味、弃之可惜的态度。
矛盾在哪里
正如引言中描述,边缘视频AI分析,是一块超级大蛋糕,那么为什么大厂却并未趋之若鹜呢?主要原因有如下几点:
- 需求碎片化:除了大交通领域视觉算法、人脸识别、车牌号识别等,其它的算法并不具备非常广泛的应用性,只是在某个场景、某个小行业,有一定的需求量,无法支撑算法场景持续性的投入成本;
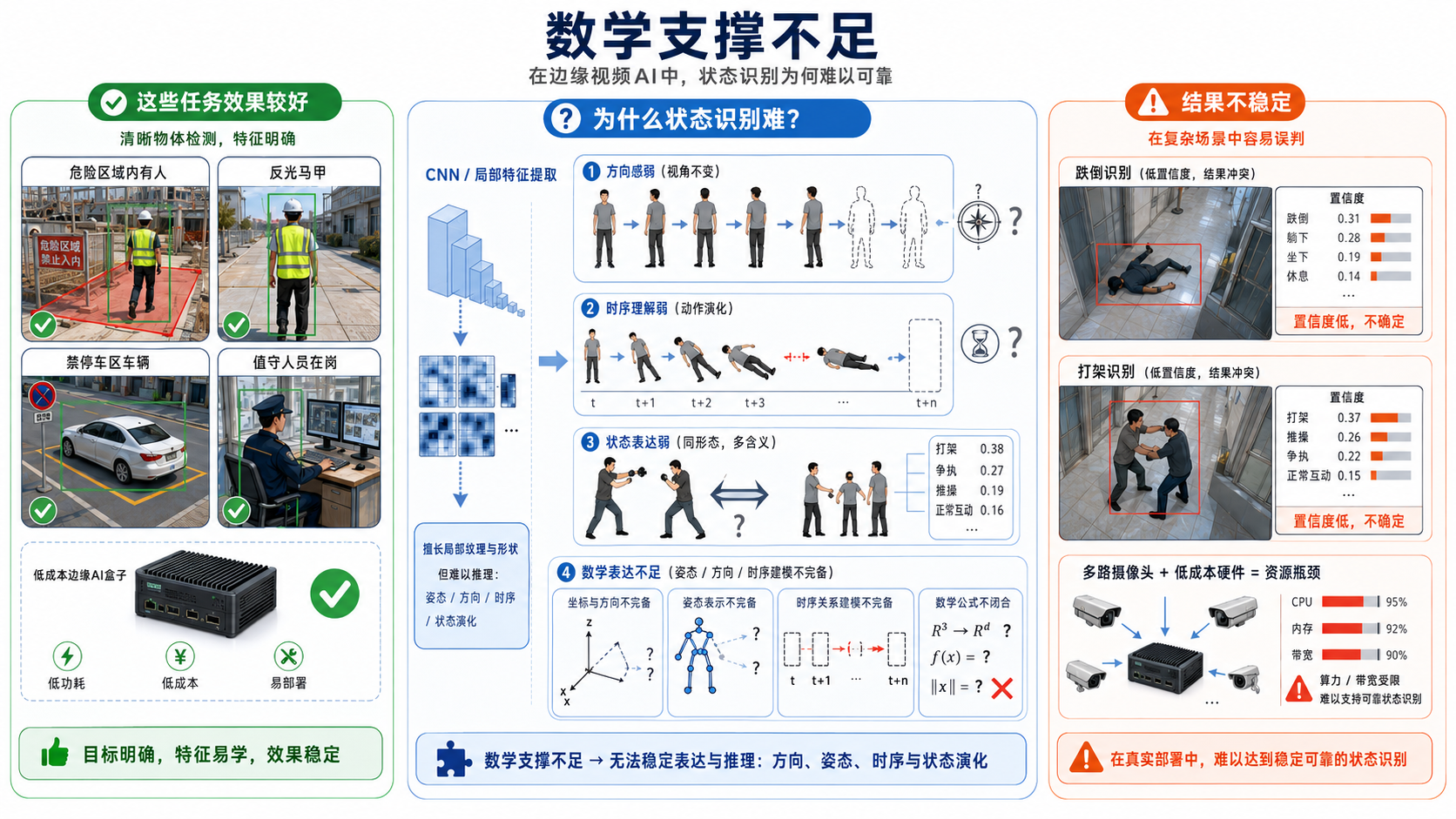
- 数学支撑不足:部分看似简单的算法缺少基础数学支撑,导致无法从根本上解决问题。比如看似简单的跌倒、打架识别算法,传统的视觉算法(如yolo等),由于特征提取器(CNN)的天然缺陷,无法彻底解决问题;
- 需求的刚需性和成本的不匹配:硬件算力成本&算法定制成本和预算的不匹配;
- 视觉小模型的能力天花板:目标检测算法在视频AI赛道占据了90%的应用场景,但是其只能针对局部像素级的分析,导致了全局理解能力不足。通常只关注局部像素的相似性,忽略了全局概念,如夜晚的红色汽车尾灯,由于局部像素跟火焰在颜色、亮度、局部纹理上具有相似性,通常会误识别为明火。正如将白云识别成烟雾,一个道理,这些都是很难仅靠传统检测算法本身彻底解决。通常要借助一些工程化的手段加以改善,但是无法根本解决。
需求碎片化
真正具备广泛通用性的场景主要有两个:人脸识别和车牌识别。这些算法大家都愿意做,因为通用性强,尤其是头部厂商,愿意投入很高的成本去做好。 另外就是交通领域违章识别,如压实线、闯红灯、未礼让行人、逆行等,虽然稍微碎片化,为什么头部大厂也愿意去做?很简单,一来是场景足够广阔,全国都能用,另一方面直接和罚款挂钩,所以动力很强。 显而易见的,如一些未佩戴安全帽、吊车下站人、地面积水、垃圾检测、沿街商贩等,由于严重的碎片化,和应用场景的局限性、买单方的购买动力等诸多原因,导致厂商不愿意投入过多的精力/资源将算法优化到极致,属于投入大、回报低。

数学支撑不足
目前在客户的应用场景,多采用机器视觉算法模型,来实现各种业务需求。如检测危险区域是否有人、是否穿戴反光马甲、车辆是否停在禁停区域、人员是否在岗,这些通过机器视觉算法,都能取得较为优秀的效果,无论是硬件价格还是算法效果,都能满足市场需求。但是对于一些状态类的算法,如人员跌倒、打架识别等,需要在安防相机视角下,通过廉价的边缘算力盒子,既能实现较好的分析效果,又能同时承载较多的摄像头数量,是不现实的。 这主要是由于机器视觉算法的基础特征提取器,多采用卷积神经网络(CNN),这个神经网络最大的特点就是速度快,缺点也同样突出:没有方向感。也就是说一个人或者物体的状态、角度、方向,它是没有概念的,从而直接导致了这种状态类的识别需求,很难取得优秀的结果,导致在用户方落地比较困难。
需求的刚需性和成本的不匹配
我们公司曾经碰到过很多工地场景、矿山场景的需求,如检测设备的状态、人员操作规范的合规性、施工作业过程中的风险性等,这些算法需求,既深入行业,同时又面临较高的算法定制成本,很难有业主客户,会为了这样的一个需求,支付哪怕几万元的定制费用。也就导致了AI算法应用,很多时候在最后一公里倒地不起。

视觉小模型的能力天花板
视觉小模型,突出的代表就是目标检测技术,最大的特点就是:实际上它就是记忆的局部像素特征,包含颜色、形状、纹理等。比如想要识别烟雾,那么它其实只关注烟雾那一个区域,并不会关注周围的背景,如白云和烟雾在局部特征上,几乎是一模一样的,但是机器视觉算法,是不会考虑背景是否是蓝天的。同样的,火焰识别算法也是一样,它只关注那个局部特征。这也就导致了只要出现跟你想要识别的局部特征非常像的东西,就可能触发报警,从而可能会产生误报。

用大模型能解决哪些问题?
大模型的重要特点是可以用语言来定义你想识别什么内容,它天然采用了Transformer作为特征提取器,解决了CNN方向感的问题。同时,它对于目标是基于整张图像全局语义级别的理解,而不是局部像素的细节。从而能够更加准确、更加符合人类肉眼的识别能力。 同时,由于大模型能够通过自然语言,直接定义你想要识别什么内容,也就解决了需求碎片化的问题。 唯一不同的是,大模型的边缘设备,价格会高出机器视觉小模型1~2倍。但是它所能发挥的能力,其实属于性价比相对较高的选择。 利用大模型边缘盒子,既能解决前文中提到的跌倒、打架、火焰、烟雾的识别率问题,又能在多种新场景上,直接通过一句话在摄像头上实现自己的需求,商业化落地前景广阔,同时,摩尔定律在算力芯片上体现得尤为明显,大模型设备将会席卷一切,打破原有的所有机器视觉小模型的生态布局。

回复